
Rédaction WEB : JUST DEEP CONTENT
L’Intelligence Artificielle et les Graph Analytics sont les outils de Conformité de demain. Leur technologie supplante les algorithmes déterministes sur de nombreux aspects. Explications.
Le marché des solutions logicielles d’entreprise de sécurité financière et de conformité connaît une véritable révolution depuis 2015. De nouvelles technologies sont apparues permettant de véritables gains en efficacité et réduction de coûts pour les institutions financières qui s’y intéressent.
Ces institutions sont de plus en plus nombreuses à sauter le pas. Bien entendu, toutes affichent des stades de maturité inégaux sur le sujet mais aujourd’hui, aucune institution financière de premier plan, où qu’elle se trouve sur la planète, ne saurait se permettre de se détourner de cette révolution.
Le coût de la conformité a constamment progressé au cours des 20 dernières années et les institutions financières cherchent par tous moyens à optimiser leurs dispositifs de conformité.
Le recours aux algorithmes déterministes a permis la mise en place de premiers outils technologiques permettant d’automatiser un grand nombre de contrôles de conformité. Leur principe de fonctionnement connaît néanmoins des limites, y compris en termes d’efficacité.
Dès lors, le recours aux nouvelles technologies ne peut être ignoré.
Malgré la prudence des établissements assujettis et des régulateurs, tant dans les choix technologiques réalisés que dans la manière dont ils sont mis en œuvre, l’Intelligence Artificielle et les Graph Analytics sont des outils dont l’usage va devenir croissant. Point sur cette nouvelle révolution technologique.
les algorithmes déterministes : les outils jusqu’ici utilisés en conformité bancaire
Le marché des solutions logicielles de conformité existe depuis plusieurs décennies.
La première Directive européenne sur le blanchiment d’argent de 1991 (LCB/FT, Lutte Contre le Blanchiment et le Financement du Terrorisme) a fait naître une vague importante de fournisseurs que l’on peut qualifier d’historiques, encore présents sur ce marché (Mantas en 1996, Norkom et Fortent en 1998 et Actimize en 1999).
Jusqu’à très récemment, l’essentiel de l’offre disponible dans le marché reposait sur des algorithmes simples, uniquement basés sur ce que l’on appelle des « règles déterministes ».
Un algorithme déterministe est d’abord un algorithme prévisible : il produira toujours le même résultat pour la même donnée en entrée.
Un exemple de règle déterministe serait : si le montant d’un virement est supérieur ou égal à 1000 euros, alors l’algorithme fera « ABC… ».
La prévisibilité, c’est une qualité ! Une règle de détection ainsi configurée est explicable et pouvoir en expliquer le fonctionnement à son régulateur est aujourd’hui un « must » et, souvent, une obligation réglementaire !
L’inconvénient majeur d’une règle déterministe est qu’elle ne détectera que ce pour quoi elle a été programmée.
Dans l’exemple ci-avant, un dépôt espèces même s’il a des caractéristiques identiques à ce virement, ne sera pas détecté. Le logiciel ne détectera cette transaction que s’il a été configuré pour le faire.
Pour trouver ce que l’on recherche, il faudra donc que cela « rentre dans les cases ». Du coup, la banque se reposant sur ce type de détection devra, pour satisfaire aux exigences du régulateur, configurer beaucoup de règles (plus d’une centaine parfois) afin de ne passer à côté d’aucune typologie de blanchiment d’argent ou de financement du terrorisme.
Un nombre élevé de règles et des seuils bas pour ne rien laisser passer : vous avez ici une recette universelle qui conduit à la génération de beaucoup d’alertes et de presque autant de faux positifs (ces alertes de mauvaise qualité, inintéressantes). Chaque alerte devant être analysée a priori par des analystes humains.
On voit ici clairement quelques-unes des principales raisons pour lesquelles le coût de la conformité a littéralement explosé au cours des deux dernières décennies.
intelligence artificielle, graph analytics : la révolution des nouvelles technologies pour la conformité financière
On parle de révolution, de nouvelles technologies, mais de quoi s’agit-il précisément ?
Au-delà des solutions « historiques » à base de règles évoquées plus haut, le vaste univers de l’apprentissage automatique (une des branches de l’IA, l’Intelligence Artificielle, appelé « Machine Learning » en anglais) ainsi que l’analyse à base de graphes (« Graph Analytics ») revêtent un intérêt certain pour les institutions financières qui les utilisent. Voyons comment.
l’intelligence artificielle ou l’usage du machine learning en conformité bancaire
L’intelligence Artificielle, déjà présente dans de nombreux domaines, y compris de la vie quotidienne, apporte une valeur ajoutée significative dans l’optimisation de l’activité de Conformité.
Qu’est-ce que l’apprentissage automatique ?
L’apprentissage automatique est aujourd’hui partout autour de nous.
Quand les autorités chinoises trouvent une personne recherchée quelque part sur leur territoire, c’est qu’une caméra aura produit et stocké des images qu’une intelligence artificielle aura ensuite analysées, en extrayant des visages de ces vidéos et en les comparant à une base de données de ces personnes recherchées.
Lorsque votre voiture corrige d’elle-même sa trajectoire parce que son conducteur s’approche trop près du bord de la route, c’est qu’une intelligence artificielle aura détecté cette situation anormale et pris la décision d’y remédier.
Quand votre téléphone mobile effectue des actions parce que vous le lui aurez demandé par la voix (par exemple : « appelle X », « Dis-moi où se trouve le coiffeur le plus proche » …), c’est, ici encore, qu’une intelligence artificielle aura « compris » ce que vous lui demandez et aura traduit cet ordre en une action qu’elle sait réaliser.
En matière de solutions de Sécurité Financière, l’apprentissage automatique est aujourd’hui préconisé et utilisé pour plusieurs cas d’usage distincts.
Intelligence Artificielle : quelle utilité en Conformité financière ?
En premier lieu, l’apprentissage automatique permet à un ordinateur d’« apprendre » ce qu’est une bonne alerte (un « vrai positif »).
Cet apprentissage est réalisé en soumettant à l’algorithme le plus possible d’exemples d’alertes considérées comme de vrais positifs par des analystes humains dans le passé. On parle alors d’apprentissage « supervisé » (« Supervised Machine Learning » en anglais) ou « semi-supervisé », selon les cas, en ce sens que l’on « supervise » l’algorithme en lui montrant la voie.
L’intérêt pour ce type d’approche est clair : si un ordinateur peut automatiquement classifier les alertes générées en tant que vrais et faux positifs, il le fera en une fraction de seconde, soit beaucoup plus rapidement que ne pourrait le faire un analyste humain qui, lui, aura besoin de plusieurs minutes par alerte pour arriver à un résultat comparable.
Autre intérêt, chaque alerte clôturée devant faire l’objet d’une explication sous forme de texte, l’algorithme pourra la générer en une fraction de seconde, ce qui représente ici encore un gain de temps très substantiel par rapport au travail manuel d’un analyste humain. Pour plus de sécurité, on peut même demander à l’algorithme de prendre une décision de clôture ou d’escalade des seules alertes pour lesquelles son degré de confiance (vrai ou faux positif quasi-certain) est très élevé.
S’agissant des alertes pour lesquelles un doute raisonnable subsiste, un analyste humain pourra tout à fait les revoir manuellement. Quoi qu’il en soit, la somme de ces minutes de traitement gagnées au niveau de chaque alerte peut représenter des centaines de milliers voire des millions d’euros chaque année pour une institution financière, selon la taille de ses opérations. Les économies induites par cette solution peuvent représenter jusqu’à 90% des coûts de traitement humain.
L’apprentissage automatique peut également être utilisé au stade de la détection, c’est-à-dire en amont de l’exemple mentionné au paragraphe précédent. En matière de lutte contre la fraude, par exemple, on peut tout à fait « apprendre » à un algorithme (supervisé, donc) à quoi ressemble une transaction frauduleuse afin d’en stopper les effets le plus rapidement possible.
Pour ce faire, à nouveau, l’institution financière doit soumettre à l’algorithme le plus possible de cas de fraude avérés de sorte que la qualité de la détection soit optimale. Il n’est pas toujours possible, même après un certain délai, d’acquérir la certitude qu’une transaction est frauduleuse ou pas. En matière bancaire, qu’il s’agisse de chèques, de carte ou de prêts à la consommation, les chiffres de la fraude mûrissent assez rapidement et après un mois ou deux, on obtient des données relativement « propres » pour pouvoir les soumettre à un algorithme d’apprentissage automatique. Il s’agirait en effet de ne pas biaiser son apprentissage avec par exemple des exemples de transactions non frauduleuses qui, en définitive, seraient déclarées comme frauduleuses quelques semaines plus tard.
L’intérêt de cette approche est assez évident : stopper la fraude en temps réel avant que l’argent ne quitte les caisses de la banque, ce qui permet de réaliser très rapidement des économies substantielles. D’autant plus qu’en France, l’impact financier de la fraude est généralement supporté par les établissements financiers, sauf à ce que ces derniers ne parviennent à démontrer que le client porteur des moyens de paiement en question a été négligeant (par exemple, report du code secret de carte bancaire sur un post-it dans le portefeuille).
En dernier lieu, il existe une branche de l’apprentissage automatique qui n’a pas besoin qu’on lui apprenne ce qui est problématique et ce qui ne l’est pas, à la différence des deux exemples précédents. On parle donc ici d’apprentissage « non supervisé » (« unsupervised machine learning » en anglais).
Pour simplifier l’explication, ces algorithmes permettent de trouver des anomalies dans les données qui lui sont soumises. On parle d’ailleurs « d’anomaly detection » en anglais, ou détection d’anomalies en français. Très souvent, il s’agit de séries de données dans lesquelles l’algorithme perçoit une décorrélation, c’est-à-dire un écart inhabituel entre plusieurs séries de données préalablement mieux ou différemment corrélées.
Par exemple, un client pouvait appartenir à un « groupe de pairs » ou « cluster » particulier quant à la fréquence ou au montant global de ses transactions jusqu’à récemment et, pour une période plus récente, l’algorithme détecte que le client en question en est sorti à la faveur de transactions plus fréquentes ou de montants globaux plus élevés que d’habitude.
On dit souvent que l’intérêt pour ce type de détection est de contrebalancer le biais des règles déterministes : ces dernières ne trouvent que ce qu’on leur a demandé de trouver, tandis que l’apprentissage automatique non-supervisé fait exactement le contraire, à savoir chercher les anomalies jusqu’alors inconnues de l’institution financière (les fameuses « unknown unknowns » en anglais).
On touche ici au « graal » des métiers de détection en conformité : trouver tout ce qui doit l’être et non juste ce qui peut l’être.
graph analytics : l’apport technologique de l’analyse à base de graphes
L’analyse à base de graphes (« Graph Analytics » en anglais), quant à elle, complète une installation traditionnelle à base de règles ou utilisant l’apprentissage automatique. On peut utiliser les graphes au stade de la détection et/ou à celui de l’adjudication des alertes.
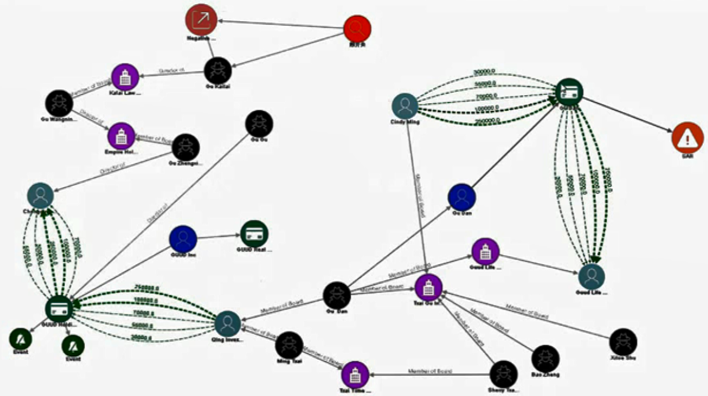
Source : Oracle
L’exemple ci-dessus montre ce qu’est un graphe. Il s’agit d’une représentation visuelle d’entités reliées entre elles d’une façon ou d’une autre. Une entité peut être une personne, un compte, un moyen de paiement, une alerte, une adresse … Un lien peut-être une transaction (par ex. ‘X’ envoie de l’argent à ‘Y’), un lien de possession (par ex. ‘X’ est titulaire du compte ‘Y’, ou ‘X’ détient 20% du capital de la société ‘Y’).
On perçoit assez rapidement les apports des graphes par rapport à l’approche traditionnelle des règles déterministes :
- les règles produisent généralement des résultats sous la forme de matrices, qui peuvent être difficiles à analyser de manière holistique lorsque le nombre de résultats est élevé.
- ces résultats sont souvent unidimensionnels en ce sens qu’ils renvoient rarement les résultats obtenus de manière consolidée à travers les différentes entités de données d’une même problématique : transactions, personnes, comptes, produits financiers …
- enfin, les règles permettent très difficilement de voir au-delà du premier degré de séparation. Les graphes, eux, gomment l’ensemble de ces biais.
En tant qu’outil de détection, on peut facilement configurer une solution à base de graphes de sorte qu’elle alerte sur des schémas de trafic d’êtres humains ou d’espèces animales protégées, par exemple. Les graphes auraient tout aussi pu aider à découvrir plus tôt les escroqueries au carrousel de TVA dans les années 1990.
La possibilité offerte par les graphes de voir au-delà du premier degré de séparation est également d’une aide certaine. En effet, savoir qu’un client de la banque est lié à une autre personne (premier degré) qui elle-même est liée à une autre personne (deuxième degré) et que cette dernière est une personne apparaissant sur une liste de sanctions internationales, situation compliquée à détecter au moyen de règles, est un apport indéniable aux solutions classiques.
Au stade de l’adjudication des alertes, les graphes apportent une plus-value certaine. Ils permettent justement à un analyste :
- d’avoir une vue d’ensemble de la situation d’une personne ou d’un compte objet de l’alerte sur laquelle il travaille,
- de comprendre les liens entre ces entités ou avec des alertes ou des entités tierces,
- comprendre celles de ces entités liées qui pourraient être sanctionnées ou politiquement exposées (PPE) ou pour lesquelles des informations à connotation négative existent dans les médias, par exemple.
Lorsqu’elles sont suffisamment puissantes, les solutions à base de graphes permettent également de lier ces entités de façon floue (« fuzzy » en anglais).
Ainsi, une personne nommée « M. Louis DUPOND » pourra être considérée comme identique à une personnes nommée « M. L. DUPOND » s’ils ont une date de naissance proche voire identique, par exemple. Sans cette fonctionnalité cruciale, aucune correspondance ne pourrait être faite entre ces deux entités alors qu’il s’agit à l’évidence de la même personne. Ce qui restreindrait, par construction, la vision d’un analyste à une partie seulement de l’histoire du client sous investigation.
L’application de ces nouvelles technologies au domaine de la Sécurité Financière et de la Conformité est assez récente puisqu’elle date à peu près du milieu des années 2010, alors même que le concept d’apprentissage automatique existe depuis les années 1960 et que les prémices de la théorie des graphes datent de… 1736 (publication du problème mathématique nommé « Les 7 ponts de Königsberg » par Leonhard Euler) !
Seulement, le passage de la théorie à la pratique en ces domaines nécessite une certaine puissance informatique (surtout s’agissant des graphes).
L’explosion des capacités informatiques et du « cloud computing » au cours de ces dix dernières années, cumulée à l’inflation des coûts de conformité, ont grandement facilité l’avènement de la révolution en cours.
a quand une révolution technologique en conformité financière ?
A lire ce qui précède, l’on pourrait tout à fait se poser la question de l’avènement d’une véritable révolution, celle du remplacement pur et simple des règles déterministes par ces nouvelles technologies. Certains éditeurs spécialisés ne proposant que des solutions à base d’apprentissage automatique en font d’ailleurs la promotion. La mort des règles, selon eux, serait imminente !
Mais cette transformation tarde à arriver et n’arrivera probablement pas de sitôt.
Premièrement, comme expliqué ci-avant, les règles ont un avantage que l’apprentissage automatique n’a pas toujours : elles sont facilement compréhensibles et explicables. Un algorithme d’apprentissage automatique est d’autant plus explicable que sa logique de détection est simple et certains algorithmes sont très complexes. Adieu, donc, l’explicabilité dans certains cas.
Et c’est bien là que se situe le problème : une alerte générée doit être explicable aux yeux des régulateurs.
Si un établissement ne sait pas expliquer comment ses algorithmes fonctionnent, ni pourquoi telle ou telle alerte a été générée, comment saura-t-il convaincre ses régulateurs qu’il a confiance dans la couverture de ses risques ?
Que les règles soient compréhensibles est également un atout : les équipes d’analystes LCB–FT à travers le monde ont été formées à leur utilisation depuis des décennies.
Une approche transformative radicale vers ces nouvelles technologies nécessiterait à la fois un effort de formation important et une évolution du profil des équipes de Conformité et de gestion des Risques vers des profils beaucoup plus « matheux ». Ce qui suppose un budget plus important, alors que l’objectif poursuivi par les établissements financiers à l’heure actuelle est justement la réduction des coûts.
Intelligence Artificielle, Graph Analytics, les nouvelles technologies permettent des gains en efficacité et en productivité réels et les institutions financières ne s’y trompent pas : elles s’en saisissent massivement depuis 2015.
L’usage de ces nouveaux outils reste néanmoins loin de se généraliser. Ces nouvelles technologies restent le plus souvent utilisées en particulier aux fins d’amélioration d’une partie du dispositif LCB–FT. Il faut dire que remplacer un système dans son ensemble est parfois compliqué, souvent coûteux et long. Il induit aussi beaucoup de changements, notamment au niveau des équipes opérationnelles.
Quant aux régulateurs, la majorité d’entre eux embrasse la révolution en cours et l’encourage même, pour certains, tout en soulignant qu’il est nécessaire de rester en conformité avec la réglementation, quels que soient les dispositifs de supervision employés par les établissements assujettis.
Que faut-il comprendre par-là ? Que les établissements doivent rester à la pointe de l’innovation et s’équiper des toutes nouvelles technologies et approches disponibles dans le marché, mais que les économies générées par ces nouveaux outils ne sauraient se faire au détriment de la maîtrise de leurs risques de blanchiment d’argent et de financement du terrorisme.
Auteur
Frédéric Boulier ![]()
Global Head of Solution Consulting, Membre du jury du prix « Finance : Ethique & Confiance », Observatoire de la Finance – ESBanque
Sources :
- Directive 91/308/CEE du Conseil, du 10 juin 1991, relative à la prévention de l’utilisation du système financier aux fins du blanchiment de capitaux
- New technologies and anti-money laundering compliance – Financial Conduct Authority – PA Consulting group – 31/03/2017
- Joint statement on innovative efforts to combat money laundering and terrorist financing –12/03/2018
- ACPR – Pôle FinTech et Innovation


L’apprentissage non supervisé est utilisé par l »ACPR dans le cadre de son outil Lucia développé avec la Banque de France pour les contrôles sur l’efficacité du dispositif LCB-FT des établissements audité.
Cet outil a été présenté lors de la conférence ACPR du 25 novembre 2021.
Voir page 88 et suivantes de la présentation : https://acpr.banque-france.fr/sites/default/files/media/2021/11/26/20211126_presentations_des_intervenants_de_la_matinee.pdf